
This article tries to summarize Autobahn, a new BFT protocol published in SOSP 24. The original paper can be found here: https://arxiv.org/abs/2401.10369
Background & Problem Statement
We first define a few terms to state the goal of this paper
- Blip: periods during which protocol stops making progress. This includes network asynchrony and other events like when a Byzantine replica is selected as a leader.
- Hangover: any performance degradation caused by a blip that persists beyond the return of a good interval. For example, after a blip, it takes time to process the client requests accumulated during blip, so new requests experience longer-than-usual delay. Some hangovers are unavoidable. E.g., even after network restoration, any protocol needs to wait until messages are delivered before making progress. Other hangovers are introduced by protocol logic and can be avoided with a better protocol design. These type of hangovers are refered to as protocol-induced.
- Seamless: a partially synchronous system is seamless if (1) it experiences no protocol-induced hangovers and (2) does not introduce mechanisms (beyond timeouts necessary for liveness) that make the protocol susceptible to blips.
This paper tries to develop a low-latency seamless BFT protocol. Existing BFT protocols comes in 2 flavors:
Traditional BFT protocols (e.g., PBFT, HotStuff) assume a partially synchronous network where messages can be delayed up to some global stabilization time (GST). These protocols often involves a leader proposing a batch of requests (a block) and other replicas exchange vote messages to decide if the proposed block should be committed. This approach delivers low latency when network is stable by minimizing number of message exchanges between replicas. However, these protocols often suffer from hangovers due to queueing delay: when a blip ends, new transactions experience longer latency than usual as replicas try to clear up the requests accumulated during the blip. This hangover can be mitigated by proposing a huge batch of requests that includes all requests accumulated during blips and new requests, but sending such a huge batch is inherently slower than normal due to limited network bandwidth. If you always send such a huge batch then latency will increase as replicas need to wait for enough requests for a batch.
Direct Acyclic Graph (DAG) based BFT protocols (e.g., HoneyBadgerBFT, Tusk) assume asynchronous network. Each replica independently propose blocks through reliable broadcasts. Each block will point to some earlier blocks as its parents and thereby forming a DAG. To overcome FLP impossibility, these protocols use randomness when deciding if a block should be included in the final DAG. While they can immediately make progress when network restores, each reliable broadcast requires significant number of message exchanges, leading to high-latency. Furthermore, voting for a block often requires having all its ancestors. If a replica is missing some blocks, it may need to fetch them from others before they can vote for new blocks, leading to potential protocol-induced blips.
In summary, a seamless BFT protocol needs to:
- Disseminate blocks asynchronously and independently from consensus ordering.
- After a blip, either all blocks disseminated during blip can be committed immediately when they are delivered, or the replicas can start working on new requests as usual and the blocks disseminated during blip can be committed when the new requests are committed.
- Replicas can vote even if it is missing some blocks.
Autobahn
Autobahn adopts the classic assumption of $n=3f+1$ where $n$ is the number of replicas and $f$ is the maximum number of faulty replicas it can tolerate. Autobahn is composed of a block dissemination layer and a consensus layer.
The block dissemination layer ensures that at least one correct replica stores the block so other replicas can always reliably fetch it as needed. In Autobahn, each replica independently batches the requests it receives into blocks and broadcast the block to other replicas in a propose message. Upon receiving a valid propose message from peers, the replica will respond with a vote message. When receiving $f+1$ votes for a proposal, replica can compose these $f+1$ votes into a proof of availability (PoA) indicating that this block is durably stored by at least 1 correct replica and everyone can reliably fetch the block whenever needed. The PoAs are sent to leader and passed to consensus layer. This process of proposing a block and composing the votes into its PoA is called Certification of Available Requests (CAR).
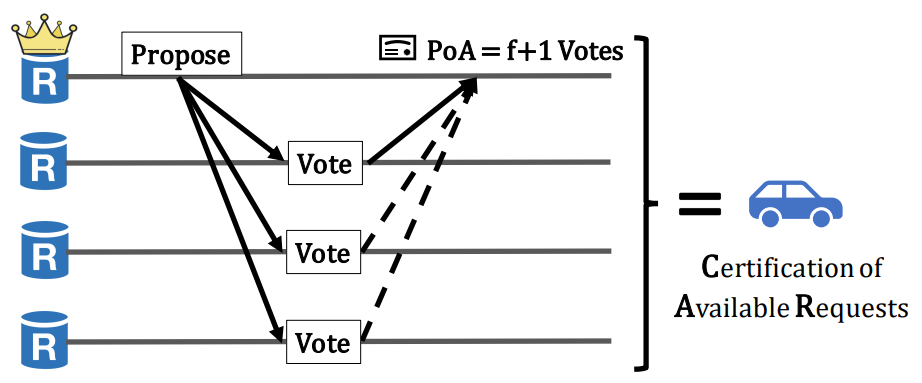
CARs started by the same replica form the replica’s lane. Lastly, Autobahn adopts the chaining idea and each propose message includes the hash of its parent block (proposed by the same replica) and its PoA. When a replica receives a valid propose message, it will only respond with a vote if (1) it has voted for its parent block and (2) it has not yet voted for another block at the same height. However, since PoA only requires $f+1$ votes, there can still be multiple blocks, each with a PoA, at the same height, meaning that lanes can diverge. This is fine as the consensus layer will decide which branch of the lane will be committed.
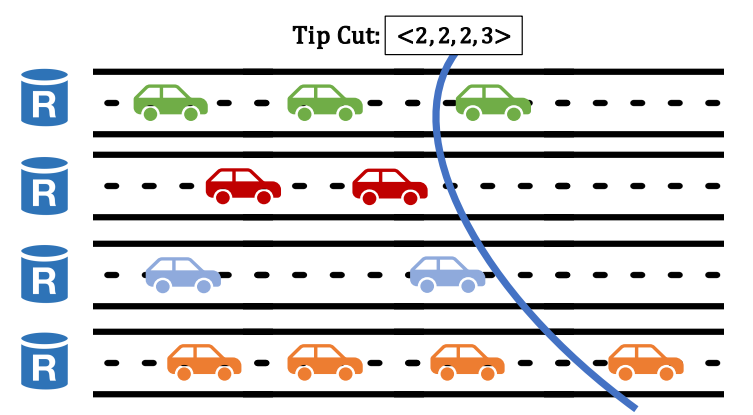
Autobahn’s consensus layer follows a classic two-round linear PBFT-style agreement pattern. Instead of proposing blocks, the leader proposes one block with PoA from each lane, forming a lane cut. When a cut is committed, every block in the cut, along with its ancestors up to the previous cut, are committed. The ordering of these blocks are determined locally at each replica through some deterministic algorithm on the set of committed blocks. To achieve seamlessness, the proposed cut includes the PoA for the blocks to convince correct replicas that this cut is safe and they can fetch any missing blocks asynchronously after the blocks are committed. The consensus protocol proceed in (log) slots. For each slot, leader proposes a cut and wait for $2f+1$ votes from replicas indicating they locked in on this proposal (and they will not vote for another proposed cut for this slot) in the prepare phase. It then compose these votes into a quorum certificate (QC), send it to the replicas, and wait for their votes indicating that the decision is durably stored in the confirm phase. Finally, it composes votes from the confirm phase into another QC and send it to replicas for commit before moving to the next slot (5 message delays in total). As an optimization, if the leader receives all $n$ votes during the prepare phase, that means all $2f+1$ correct replicas have locked in for this proposal. When a view-change happens, the new leader will receive this proposal from at least $f+1$ correct replicas. This is sufficient to ensure that the proposed cut is durable and the confirm phase is not needed, enabling a 3-message-delay fast path.

As with other BFT protocols with partial synchrony assumption, Autobahn relies on timeouts for liveness. If the leader does not propose for a while, replicas will send timeout message including the proposed cut in its last locked-in slot to the next leader. The consensus layer then proceeds as with the classic two-round linear PBFT. One important nuance is that, since lanes can diverge, the new leader may not agree with the old leader on the diverging blocks they have voted for during dissemination. As a result, the new leader may include a block in its proposed cut that does not extend from a block that has committed in the previous round by the old leader. In this case, replicas will only commit the ancestors of the new block whose heights are greater than the block in the last committed cut so that for each lane, only one block gets committed at each height, even if they do not necessarily extend from each other. Note that proposed cuts are monotonic since the latest cut replicas observe at the end of a slot instance is at least the proposed cut during the round.
Optimizations
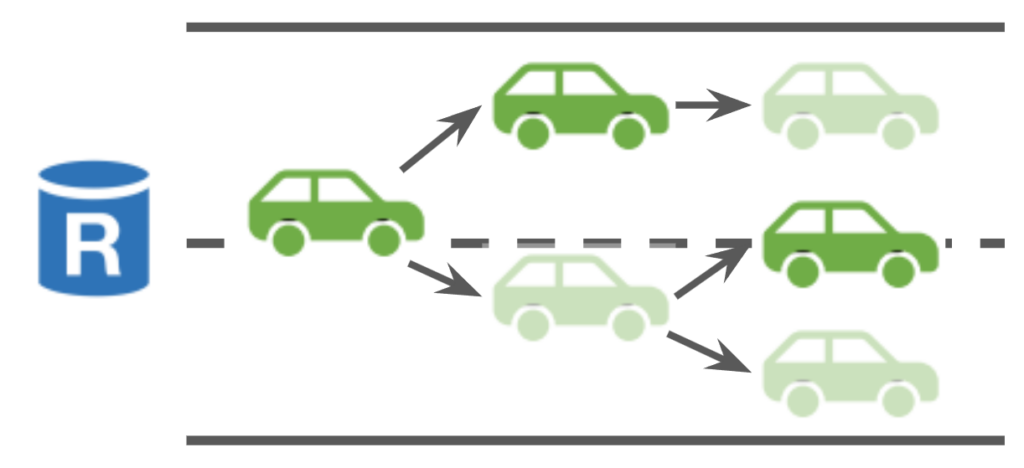
Parallel Multi-Slot Agreement: In Autobahn, new slot instances can run in parallel with previous slots instead of having to wait for them to commit. Enabling such concurrent consensus requires a few modifications include: (1) when a proposed cut is committed at a slot, replicas need to wait for all the proposed cuts in the previous slots to execute before executing this one; (2) proposed cuts are no longer monolithic so replicas need to ignore out-dated blocks in the new cut; (3) leader do not need to wait for the previous cut to be committed before proposing a new cut, so timeout should start when the previous cut is proposed instead of when the previous cut is committed; (4) in case all parallel slot instances view-change through the same Byzantine leader, the leader election schedule for each instance is offset by $f$; (5) in case there are too many parallel instances during a blip, the number of parallel instances is restricted by some $k$, so slot instance $s$ cannot start until slot instance $s-k$ is committed. The paper points out that this approach is better than pipelining consensus phases (e.g., Chained HotStuff) as (i) this incurs lower latency since new proposals don’t need to wait for the previous phase to finish, (ii) this approach does not introduce new liveness concerns, and (iii) slot instances run independently and failing of one slot instance does not affect the progress of other slot instances.
Pipelining CARs: CAR for a new block can start without waiting for its parent block’s CAR to finish. Yet doing so means malicious validators can flood the network with blocks that will never commit.
Proposing Uncertified Cuts: Autobahn can further reduce latency by including blocks without PoA (uncertified blocks) in proposed cuts. One intuitive example is for leaders to include uncertified blocks in its own lane. Byzantine leaders may include unavailable blocks but correct replicas will simply realize that the block is unavailable when it tries to fetch the block and issue a view-change requests. A more aggressive approach allows the leader to optimistically include uncertified blocks from other validators. This approach hides two message delays (one for vote to the proposer and one for proposer sending the PoA back to leader) required for block dissemination from the critical path. However, this design sacrifices seamlessness as followers still needs to wait for PoA before voting. As a mitigation, during consensus, replicas can issue weak votes if it has not vote for another cut at the slot and strong votes if it additionally has the block data or PoA. This way, a quorum with $f+1$ strong votes can serve as its PoA.
Others: threshold signature to reduce size of quorum certificate; use all-to-all communication instead of linear to latency (each phase only incurs one message delay instead of two).
Strength
- Autobahn achieves low latency. It only adds 3 message delays to the BFT protocol it uses for consensus. Client requests leader receives will experience 1 less message delay since it does not need to broadcast PoA. With the linear PBFT-style protocol it used in the paper, its latency is comparable with HotStuff.
- Autobahn achieves high throughput. Its throughput is bounded by the block dissemination layer (no matter how fast block dissemination layer disseminates blocks, the consensus layer can always commit everything by voting on tip cut) and thereby achieve throughput comparable to DAG-based BFT protocols like Bullshark.
- Autobahn is free from censorship: blocks proposed by any validator will eventually get included in some cut proposed by a correct leader. This design also provides basic chain quality as blocks by benign validators will be included on chain eventually.
- Autobahn is resilient to blips: The only source of hangover left is that new requests may experience additional queueing delays if the receiving validator is waiting for its lane tip to get certified. However, to remove this hangover, the validators need to be able to start CARs unboundedly, and Byzantine validators may be able to flood the network with invalid blocks.
Weakness
- Autobahn’s network complexity is higher than normal BFT protocols, as the message size of proposed cut has complexity of $O(n)$. This can limit its scalability. One may argue that Autobahn can commit much more than $n$ blocks in one consensus round (compared with HotStuff where each round trip only commits one block), and consequently validators actually exchange less bytes of messages to commit these blocks. However, this is only true if the leader has waited for long enough so that sufficiently many blocks have been disseminated between two rounds of consensus. Yet waiting for too long will lead to long latency. Care needs to be taken when pacing the consensus layer.