In the previous post I tried to summarize the Autobahn paper but its goal, seamlessness, seem convoluted. In this post, I will try to explain it in my own way so that hopefully it can be easier to understand and get myself an internship at Ethereum Foundation 🙂
Background & Motivation
We assume $f$ faulty validators and a total of $n=3f+1$ validators. We will still start by defining blips.
Blip: a period during which protocol does not make progress. This include network asynchrony, Byzantine leader elected, etc.
Existing practical BFT protocols can be largely categorized as partially synchronous and asynchronous, depending on their network assumptions. Traditional wisdom says that partially synchronous protocols deal poorly with blips. Asynchronous protocols can handle blips well as they proceed at network rate, but perform poorly during good periods due to excessive amount of message exchanges requred to ensure consensus. So this paper asks: why do partially synchronous protocols deal with blips so poorly? Can they do better?
Hangovers
Hangover: performance degradation caused by blips that lasts after blips end
Since no protocol can make progress during blips, the previous question can be rephrased as, why do partially synchronous protocols experience more serious hangovers than asynchronous protocols and how can we mitigate hangovers.
Take HotStuff as an example, after blips end and timeouts expire, a new benign leader is elected. It will batch client requests into a block, send the block out, collect votes, and send the collected votes with the next block of client requests. Since there are requests coming in during blips, new requests received after blips need to be queued after the old requests, leading to hangovers. So the key to the previous question is, how can we process requests accumulated during blips as fast as possible?
Separate Block Dissemination from Consensus
One existing technique is to separate block dissemination (sending block to other validators) from consensus ordering. The key observation is that consensus messages are often small, whereas blocks themselves are orders of magnitude larger, so removing block dissemination from consensus cirtical path can significantly reduce latency. Aptos, for example, uses Narwhal for block dissemination and Jolteon for consensus.
Autobahn similarly adopts this technique. It has an asynchronous block dissemination layer that ensures blocks can be disseminated even during blips and a consensus layer to pick from these blocks for ordering. However, in a naive implementation, since validators need to possess the blocks proposed by the leader before voting, the leader must pick blocks that all $2f+1$ benign validators have received, or they will request the blocks from peers before voting, moving block dissemination back onto the critical path. Yet a block dissemination layer that guarantees this inevitably require numorous message exchanges. Can we do better?
Proof of Availability (PoA)
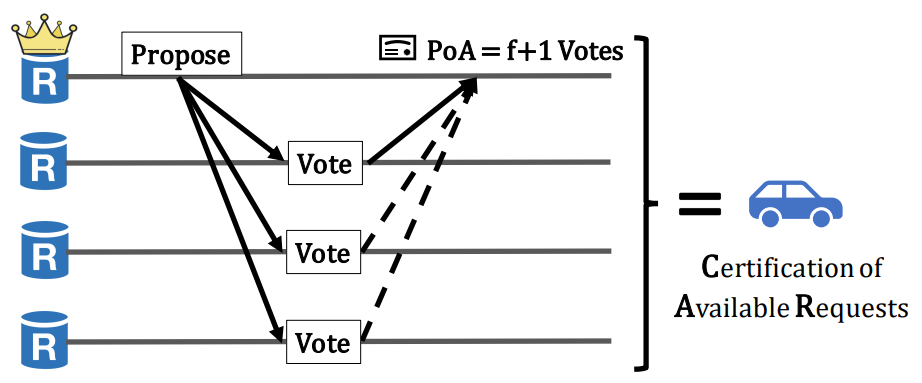
Turns out validators do not need to validate the exact requests in blocks during consensus ordering – they can ignore bad requests during execution. So a benign validator can vote if the leader can convince it that the blocks will be available when needed. This weak guarantee only requires one benign validator to persist the block and use collision resistant hashes to ensure Byzantine validators cannot lie about block content. To provide this guarantee, during block dissemination, each validator will broadcast its blocks and wait for $f+1$ votes from peers, which it will combine to form a Proof of Availability (PoA). This process is called Certification of Availability Requests (CAR).
Certification of Available Requests
In Autobahn, validators broadcast blocks with the PoA of its parent block, forming a chain. This chain of CARs is called a lane and the last poposed block in a lane is called a tip. Each validator has its own lane. Byzantine validators may not always append new blocks to lane tip, leading to forks. Benign validators will only vote for a block if it has previously voted for its parent and it has not voted for another block by the same proposer at the same height. This way, PoA for one block proves the availability of all its ancestors.
However, since PoA only require $f+1$ votes, there can be blocks with PoAs at the same height and lanes can diverge. The consensus layer will choose one branch to commit.
Consensus
Autobahn can choose any BFT protocol for its consensus. The key is to include as much PoA as possible in the leader’s proposal. Once validators agree on the set of blocks to commit, they can locally decide how these blocks should be ordered locally through some deterministic algorithms.
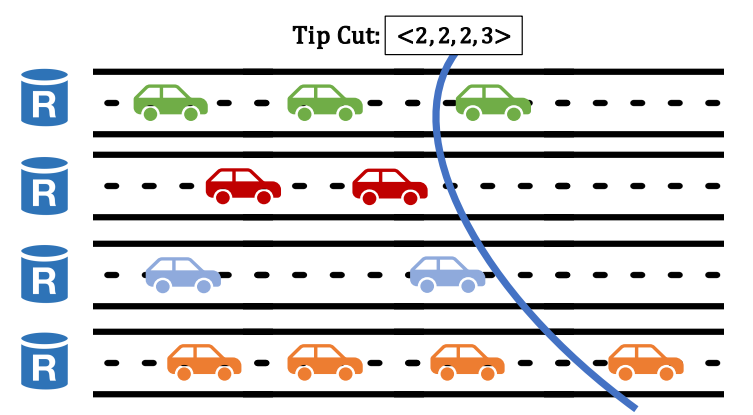
Validators each manage a local view of all lanes. The leader will pick out the last certified tip (tip with a matching PoA) of every lane in its local view, forming a tip cut. The leader will include this tip cut in its proposal.
Lanes and Tip Cut
When this proposal is committed, the blocks in the proposed tip cut, along with all its parents up to the last tip cut (committed in the last consensus round), will be committed. This way, after recovering from a blip, a single round of consensus can commit all blocks disseminated during blips, and new requests will not observe any hangovers from here.
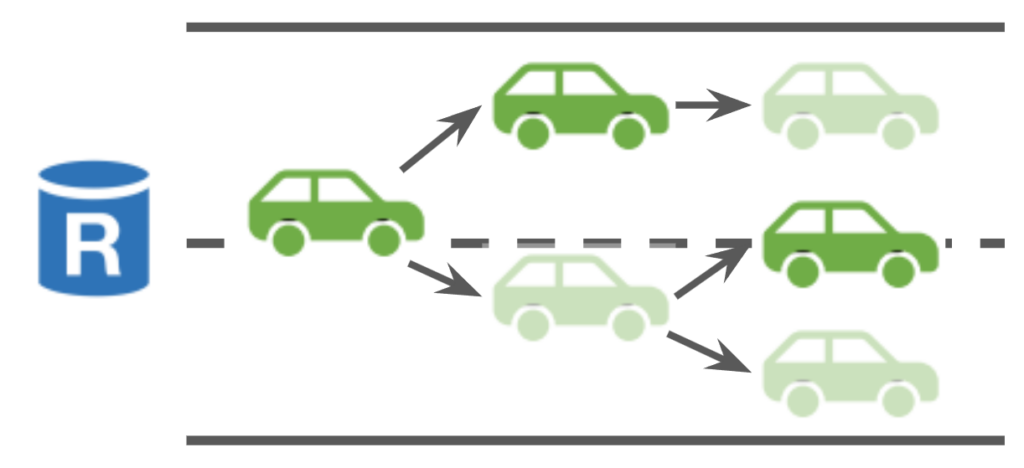
A minor problem with this design is that leaders across different views may choose tips from conflicting branches of a lane. In this case, instead of committing all ancestor blocks of the blocks in the current tip cut, Autobahn will only commit up to the block whose parent block is at the same height of the block in the previous tip cut. This means that not all committed blocks are on the same branch of the lane, but ideally this should only happen for Byzantine validators.
Committed blocks (in dark green) may be on different branches
The paper uses a linear PBFT-style protocol for consensus, where a round of consensus can be made in 1.5 round trips on the fast path and 2.5 round trips on the slow path. This latency can be reduced by using classic PBFT with all-to-all communication.
This article tries to summarize Autobahn, a new BFT protocol published in SOSP 24. The original paper can be found here: https://arxiv.org/abs/2401.10369
Background & Problem Statement
We first define a few terms to state the goal of this paper
Blip: periods during which protocol stops making progress. This includes network asynchrony and other events like when a Byzantine replica is selected as a leader.
Hangover: any performance degradation caused by a blip that persists beyond the return of a good interval. For example, after a blip, it takes time to process the client requests accumulated during blip, so new requests experience longer-than-usual delay. Some hangovers are unavoidable. E.g., even after network restoration, any protocol needs to wait until messages are delivered before making progress. Other hangovers are introduced by protocol logic and can be avoided with a better protocol design. These type of hangovers are refered to as protocol-induced.
Seamless: a partially synchronous system is seamless if (1) it experiences no protocol-induced hangovers and (2) does not introduce mechanisms (beyond timeouts necessary for liveness) that make the protocol susceptible to blips.
This paper tries to develop a low-latency seamless BFT protocol. Existing BFT protocols comes in 2 flavors:
Traditional BFT protocols (e.g., PBFT, HotStuff) assume a partially synchronous network where messages can be delayed up to some global stabilization time (GST). These protocols often involves a leader proposing a batch of requests (a block) and other replicas exchange vote messages to decide if the proposed block should be committed. This approach delivers low latency when network is stable by minimizing number of message exchanges between replicas. However, these protocols often suffer from hangovers due to queueing delay: when a blip ends, new transactions experience longer latency than usual as replicas try to clear up the requests accumulated during the blip. This hangover can be mitigated by proposing a huge batch of requests that includes all requests accumulated during blips and new requests, but sending such a huge batch is inherently slower than normal due to limited network bandwidth. If you always send such a huge batch then latency will increase as replicas need to wait for enough requests for a batch.
Direct Acyclic Graph (DAG) based BFT protocols (e.g., HoneyBadgerBFT, Tusk) assume asynchronous network. Each replica independently propose blocks through reliable broadcasts. Each block will point to some earlier blocks as its parents and thereby forming a DAG. To overcome FLP impossibility, these protocols use randomness when deciding if a block should be included in the final DAG. While they can immediately make progress when network restores, each reliable broadcast requires significant number of message exchanges, leading to high-latency. Furthermore, voting for a block often requires having all its ancestors. If a replica is missing some blocks, it may need to fetch them from others before they can vote for new blocks, leading to potential protocol-induced blips.
In summary, a seamless BFT protocol needs to:
Disseminate blocks asynchronously and independently from consensus ordering.
After a blip, either all blocks disseminated during blip can be committed immediately when they are delivered, or the replicas can start working on new requests as usual and the blocks disseminated during blip can be committed when the new requests are committed.
Replicas can vote even if it is missing some blocks.
Autobahn
Autobahn adopts the classic assumption of $n=3f+1$ where $n$ is the number of replicas and $f$ is the maximum number of faulty replicas it can tolerate. Autobahn is composed of a block dissemination layer and a consensus layer.
The block dissemination layer ensures that at least one correct replica stores the block so other replicas can always reliably fetch it as needed. In Autobahn, each replica independently batches the requests it receives into blocks and broadcast the block to other replicas in a propose message. Upon receiving a valid propose message from peers, the replica will respond with a vote message. When receiving $f+1$ votes for a proposal, replica can compose these $f+1$ votes into a proof of availability (PoA) indicating that this block is durably stored by at least 1 correct replica and everyone can reliably fetch the block whenever needed. The PoAs are sent to leader and passed to consensus layer. This process of proposing a block and composing the votes into its PoA is called Certification of Available Requests (CAR).
Certification of Available Requests (CARs)
CARs started by the same replica form the replica’s lane. Lastly, Autobahn adopts the chaining idea and each propose message includes the hash of its parent block (proposed by the same replica) and its PoA. When a replica receives a valid propose message, it will only respond with a vote if (1) it has voted for its parent block and (2) it has not yet voted for another block at the same height. However, since PoA only requires $f+1$ votes, there can still be multiple blocks, each with a PoA, at the same height, meaning that lanes can diverge. This is fine as the consensus layer will decide which branch of the lane will be committed.
Each replica has its lane and one CAR across each lane form a cut
Autobahn’s consensus layer follows a classic two-round linear PBFT-style agreement pattern. Instead of proposing blocks, the leader proposes one block with PoA from each lane, forming a lane cut. When a cut is committed, every block in the cut, along with its ancestors up to the previous cut, are committed. The ordering of these blocks are determined locally at each replica through some deterministic algorithm on the set of committed blocks. To achieve seamlessness, the proposed cut includes the PoA for the blocks to convince correct replicas that this cut is safe and they can fetch any missing blocks asynchronously after the blocks are committed. The consensus protocol proceed in (log) slots. For each slot, leader proposes a cut and wait for $2f+1$ votes from replicas indicating they locked in on this proposal (and they will not vote for another proposed cut for this slot) in the prepare phase. It then compose these votes into a quorum certificate (QC), send it to the replicas, and wait for their votes indicating that the decision is durably stored in the confirm phase. Finally, it composes votes from the confirm phase into another QC and send it to replicas for commit before moving to the next slot (5 message delays in total). As an optimization, if the leader receives all $n$ votes during the prepare phase, that means all $2f+1$ correct replicas have locked in for this proposal. When a view-change happens, the new leader will receive this proposal from at least $f+1$ correct replicas. This is sufficient to ensure that the proposed cut is durable and the confirm phase is not needed, enabling a 3-message-delay fast path.
Autobahn consensus
As with other BFT protocols with partial synchrony assumption, Autobahn relies on timeouts for liveness. If the leader does not propose for a while, replicas will send timeout message including the proposed cut in its last locked-in slot to the next leader. The consensus layer then proceeds as with the classic two-round linear PBFT. One important nuance is that, since lanes can diverge, the new leader may not agree with the old leader on the diverging blocks they have voted for during dissemination. As a result, the new leader may include a block in its proposed cut that does not extend from a block that has committed in the previous round by the old leader. In this case, replicas will only commit the ancestors of the new block whose heights are greater than the block in the last committed cut so that for each lane, only one block gets committed at each height, even if they do not necessarily extend from each other. Note that proposed cuts are monotonic since the latest cut replicas observe at the end of a slot instance is at least the proposed cut during the round.
Committed blocks in a lane. Dark green indicates that the block is committed.
Optimizations
Parallel Multi-Slot Agreement: In Autobahn, new slot instances can run in parallel with previous slots instead of having to wait for them to commit. Enabling such concurrent consensus requires a few modifications include: (1) when a proposed cut is committed at a slot, replicas need to wait for all the proposed cuts in the previous slots to execute before executing this one; (2) proposed cuts are no longer monolithic so replicas need to ignore out-dated blocks in the new cut; (3) leader do not need to wait for the previous cut to be committed before proposing a new cut, so timeout should start when the previous cut is proposed instead of when the previous cut is committed; (4) in case all parallel slot instances view-change through the same Byzantine leader, the leader election schedule for each instance is offset by $f$; (5) in case there are too many parallel instances during a blip, the number of parallel instances is restricted by some $k$, so slot instance $s$ cannot start until slot instance $s-k$ is committed. The paper points out that this approach is better than pipelining consensus phases (e.g., Chained HotStuff) as (i) this incurs lower latency since new proposals don’t need to wait for the previous phase to finish, (ii) this approach does not introduce new liveness concerns, and (iii) slot instances run independently and failing of one slot instance does not affect the progress of other slot instances.
Pipelining CARs: CAR for a new block can start without waiting for its parent block’s CAR to finish. Yet doing so means malicious validators can flood the network with blocks that will never commit.
Proposing Uncertified Cuts: Autobahn can further reduce latency by including blocks without PoA (uncertified blocks) in proposed cuts. One intuitive example is for leaders to include uncertified blocks in its own lane. Byzantine leaders may include unavailable blocks but correct replicas will simply realize that the block is unavailable when it tries to fetch the block and issue a view-change requests. A more aggressive approach allows the leader to optimistically include uncertified blocks from other validators. This approach hides two message delays (one for vote to the proposer and one for proposer sending the PoA back to leader) required for block dissemination from the critical path. However, this design sacrifices seamlessness as followers still needs to wait for PoA before voting. As a mitigation, during consensus, replicas can issue weak votes if it has not vote for another cut at the slot and strong votes if it additionally has the block data or PoA. This way, a quorum with $f+1$ strong votes can serve as its PoA.
Others: threshold signature to reduce size of quorum certificate; use all-to-all communication instead of linear to latency (each phase only incurs one message delay instead of two).
Strength
Autobahn achieves low latency. It only adds 3 message delays to the BFT protocol it uses for consensus. Client requests leader receives will experience 1 less message delay since it does not need to broadcast PoA. With the linear PBFT-style protocol it used in the paper, its latency is comparable with HotStuff.
Autobahn achieves high throughput. Its throughput is bounded by the block dissemination layer (no matter how fast block dissemination layer disseminates blocks, the consensus layer can always commit everything by voting on tip cut) and thereby achieve throughput comparable to DAG-based BFT protocols like Bullshark.
Autobahn is free from censorship: blocks proposed by any validator will eventually get included in some cut proposed by a correct leader. This design also provides basic chain quality as blocks by benign validators will be included on chain eventually.
Autobahn is resilient to blips: The only source of hangover left is that new requests may experience additional queueing delays if the receiving validator is waiting for its lane tip to get certified. However, to remove this hangover, the validators need to be able to start CARs unboundedly, and Byzantine validators may be able to flood the network with invalid blocks.
Weakness
Autobahn’s network complexity is higher than normal BFT protocols, as the message size of proposed cut has complexity of $O(n)$. This can limit its scalability. One may argue that Autobahn can commit much more than $n$ blocks in one consensus round (compared with HotStuff where each round trip only commits one block), and consequently validators actually exchange less bytes of messages to commit these blocks. However, this is only true if the leader has waited for long enough so that sufficiently many blocks have been disseminated between two rounds of consensus. Yet waiting for too long will lead to long latency. Care needs to be taken when pacing the consensus layer.
Basil is a transactional, leaderless, Byzantine fault tolerant key-value store. It leverages ACID transactions to achieve scalability in implementing the shared log in the presence of Byzantine actors. It allows non-conflicting operations to proceed concurrently.
Basil assumes partial synchrony for liveness. It uses sharding to allow for concurrent execution. In Basil, each shard, with size of $n$, can tolerate up to $f$ Byzantine actors where $n\ge 5f+1$. An arbitrary number of clients can be faulty. However, despite the presence of Byzantine actors, Basil assumes that they are well-behaved in most cases. It achieves high performance in the benign cases, allowing a transaction to commit within 1 RTT in the best case.
This paper introduces two notions of correctness, which they lay the foundations for Basil on: Byzantine isolation and Byzantine independence. Byzantine isolation, or Byz-serializability, states that clients will observe a sequence of states that is consistent with a sequential execution of concurrent transactions. Byzantine independence, on the other hand, states that for every operations issued by a correct client, no group of participants containing solely Byzantine actors can unilaterally dictate the result of this operation (i.e. the no decision can be made by Byzantine actors only). Basil’s design follows the principle of independent operability, meaning that it enforces safety and liveness through mechanisms that operate on a per-client and per-transaction basis. This allows the clients to fetch all necessary information and send them to replicas to make the decision: clients serve as the leader to coordinate operations and no communication is needed directly between any pair of replicas in most cases.
Transaction Processing
In Basil, an operation proceeds in 3 phases, an Execution phase, a Prepare phase, and a Writeback phase. During the Execution phase, the client locally executes individual transactional operations. The result is broadcasted to all replicas in each involved shards during the Prepare phase for vote. The vote results are aggregated to determine the outcome of the transaction to create a certificate, which is forwarded to replicas in the Writeback phase, after which the replicas can proceed asynchronously to complete the operations.
Basil’s serialization protocol is a variant of multiversioned timestamp ordering (MVTSO), an optimistic concurrency control protocol. The traditional MVTSO works as following: each transaction is assigned a unique timestamp that determines the serialization order. Entries written in this transaction are tagged with this timestamp, and reads in this transaction updates the corresponding entries’ read timestamp (RTS). MVTSO ensures that, for each transaction with timestamp $ts_1$, writing an object with RTS $ts_2>ts_1$ will fail (write after a future read), and reading an object always returns a version tagged $ts_3<ts_1$.
In Execution phase, a client constructs a transaction $T$ locally with one call to begin() and several read(key) and write(key, value) calls. begin() adds a client chosen timestamp $ts_T$ for MVTSO. Since committing a transaction with huge timestamp can block future execution indefinitely, each replica accepts a transaction only if the difference between this timestamp and the replica’s local timestamp is bounded by some $\delta$. Basil buffers all write(key, value) locally in a $WriteSet_T$ and they are not visible to the replicas until the Prepare phase. As for read(key), the client sends a read request <READ, key, $ts_T$> to at least $2f+1$ replicas in the shard the key belongs. Each replica will check if this request has a valid timestamp. If it does, each replica locally updates the corresponding key’s RTS with this timestamp and returns two versions, the committed version and the prepared version. The committed version will come with a commit certificate and the prepared version comes with the id of transaction $T’$ that creates this version as well as a set $Dep_{T’}$ including all transactions that should commit before $T’$. The client considers a committed version as valid if any replica provides a valid commit certificate and it considers a prepared version as valid if the same version is returned by at least $f+1$ replicas. It selects a valid version with the highest timestamp to add to its $ReadSet_T$. If the version is prepared but not committed, it also adds $T’$ to $Dep_T$.
After the Execution phase completes, Basil proceeds to the Prepare phase, which consists of a stage 1 and an optional stage 2. In stage 1, the client sends the entire transaction $T$ to all replicas in all shards involved in $T$, including $ts_T$, $ReadSet_T$, $WriteSet_T$, and $Dep_T$. Each replica then locally runs MVTSO to check if $T$ can be committed. Specifically, it votes for commit if (1). $ts_T$ is valid, (2). all versions in $ReadSet_T$ are before $ts_T$, (3). all entries touched in $WriteSet_T$ have an RTS before $ts_T$, (4). it does not conflict with another on-going transaction, and (5). all transactions in $Dep_T$ are committed (it waits until they are either committed or aborted). Then the replicas forward their decisions to the client, who will determine (1) if $T$ should be committed or aborted, and (2) if stage 2 is needed.
Stage 2 is intended to make the transaction $T$ durable. Here durability means that, if in the future another client queries about $T$, it will see the same result (committed or aborted) as the client issuing this request. For the replies from replicas within any shard, the client checks for following:
Commit Slow Path: $3f+1\le\text{Commit votes}<5f+1$. Here $3f+1$ commit votes ensures that two conflict transactions cannot both commit ($2\times(3f+1)-n=f+1>f$).
Commit Fast Path: $\text{Commit votes}=5f+1$. In this case all replicas reports a conflict and any client will be guaranteed to receive at least $3f+1$ commit votes. Notice that when $n=5f+1$, a client will wait on responses from $4f+1$ replicas to preserve liveness in presence of network-partitioned faulty replicas, amongst which $f$ of them may be Byzantine actors.
Abort Slow Path: $f+1\le\text{Abort votes}<3f+1$. Here $f+1$ abort votes ensure that at least one correct replica detects a conflict. Notice that a transaction may still be committed in this case: there can be more than $3f+1$ replicas voting for commit and another $f+1$ replicas voting for abort ($3f+1+f+1=4f+2\le5f+1=n$). This is allowed since the equivocation may come from network delays.
Abort Fast Path: $3f+1\le\text{Abort votes}$. In this case, the shard cannot produce more than $3f+1$ commit votes ($n-(3f+1)+f=3f<3f+1$).
Abort Fast Path: one special case is for the abort fast path is that if a replica can provide the commit certificate for a transaction conflicting with $T$. In this case, since committed transactions (and hence their certificates) are durable, aborting $T$ is also durable.
If all shards proceed in the commit fast path or at least one shard proceeds in the abort fast path, then the decision is already durable and stage 2 is not necessary. Otherwise the client proceeds to stage 2.
In stage 2, the client chooses a shard voted in stage 1 deterministically based on $T$’s id to log the decision. We refer to this shard as $S_{log}$. The client will send its decision to commit or abort along with the votes it received in stage 1. It then waits for $n-f$ replies with the same decision that the corresponding replicas will log locally. Finally, the client can proceed to the Writeback phase, during which it constructs a commit certificate or abort certificate and broadcasts it to all replicas in the participating shards.
Optimizations
Creating signatures is expensive. Basil proposes to reduce the cost by batching replies. The idea is to batch multiple replies and generate a Merkle tree for each batch. Then, each reply message will include the root of Merkle tree, a signed version of the root, and the intermediate nodes necessary to get from the reply message to the root instead of the signature of the reply itself. Later when the client forwards the signature to another replica, that replica will, upon successfully verifying the signature on the Merkle root, cache the Merkle root and signature locally so that it does not need to verify it again when receiving another signature from the same batch.
Transaction Recovery
Since Basil is client-driven, a transaction may stall in the presence of Byzantine clients. This may block the other transactions issued by correct clients depending on this transaction indefinitely, breaking Byzantine independence. To prevent this, Basil allows other clients to finish the stalled transaction through a fallback protocol. In the commoncase, the replicas can reach a unanimous agreement on whether the transaction should be committed or aborted, so the client can simply resume from where the transaction was left off with.
However, there is a special divergent case where the replicas may not reach an unanimous agreement. This can only happen in one case: after stage 1 of prepare phase, within a shard, over $3f+1$ replicas vote commit and over $f+1$ replicas vote abort. At this point (during stage 2), a malicious client has enough votes to commit and to abort the transaction, so it can deliberately send different decisions to different replicas to stall the execution. Similarly, if there are multiple clients trying to finish the transaction concurrently, they may reach different decisions, leading to the same result.
Basil’s fallback protocol is similar to traditional view-change protocols. In Basil, views are defined on a per-transaction basis, with $view=0$ indicating that the message is issued by the original client that initiates the transaction. The fallback protocol (in both common and divergent case) starts with client sending a Recovery Prepare (RP) message that is identical to stage 1 request. Depending where the transaction was left off, the replicas will reply with a stage 1 reply message, stage 2 reply message, or a commit certificate or a abort certificate. In the common case, the client can resume directly from there. In the divergent case, on the other hand, the client will issue a special request InvokeFB to invoke the fallback process. In the stage 2 replies, each replica will attach its local highest view of this transaction. The client will include these view numbers in InvokeFB. Upon receiving InvokeFB, the replicas will update its current view accordingly and elect a fallback leader deterministically based on the current view. They will each send to the leader its local decision, and the leader, after receiving $4f+1$ votes, will make the final decision through majority vote, and return this final decision to all replicas. Replicas will then send a new stage 2 reply to clients interested in this transaction, who will continue to Writeback phase after receiving $n-f$ stage 2 replies with matching decision and view or restart fallback protocol otherwise.
It is worth noting that replicas within the same shard may not be on the same view for a certain transaction, in which case the fallback protocol does not produce a unanimous agreement and needs to restart. To enable fast convergence to the same view, Basil does the following: if a view $v$ appears at least $3f+1$ times in InvokeFB, the replica will update its current view to $max(v+1, view_{current})$; otherwise it sets its current view to the largest view greater than its current view that appears at least $f+1$ times in InvokeFB. Basil also adopts vote subsumption: the presence of a view $v$ in InvokeFB counts as a vote for all $v’\le v$.
Why $5f+1$?
Basil chooses $n\ge5f+1$ per shard for several reasons:
For any $n$, a client will wait for $n-f$ replies for liveness. Among these, $n-2f$ of them may vote to commit the transaction while the rest $f$ may vote to abort due to equivocation caused by network delay (so the transaction cannot be aborted). Now consider two conflicting transactions, there may be only $2\times(n-2f)-n=n-4f$ replicas that see both transactions. If we do not have $n\ge5f+1$ (i.e. $n\le5f$), then $n-4f\le f$, meaning that it is possible that no correct replica will detect the two conflicting transactions.
Smaller $n$ precludes Byzantine independence. For progress, after stage 1, the client has to be able to decide either to commit or to abort the transaction. As previously stated, committing requires at least $3f+1$ commit votes, and aborting requires at least $f+1$ abort votes due to Byzantine independence. If $n\le5f$, then with $n-f$ votes, it is possible that the client observes exactly $3f$ commit votes and $f$ abort votes, in which case the client cannot make progress.
During the fallback protocol, the fallback leader’s decision is always safe. Consider two concurrent runs of the fallback protocol on the same transaction, if one run completes and all replicas reaches a unanimous decision, then in the other run, there will be at least $n-f$ replicas agreeing on this unanimous decision. Hence, out of the $4f+1$ votes the leader receives, at least $2f+1$ will agree on the unanimous decision, reaching a majority.
Strength
Basil integrates ACID transaction and concurrency control into its BFT protocol. Experiments show that this design provides significantly better performance in real-world workloads (e.g. TPCC) compared with traditional system design where the concurrency control is implemented as an application layer on top of BFT protocols like HotStuff and PBFT.
Basil delivers splendid performance when all actors are well-behaved and there are no conflicting transactions happening concurrently: in this case, all shards involved in the Prepare phase can go through the fast path and stage 2 is not needed at all, allowing the transaction to finish within 1 RTT if it is write-only (stage 1 request and reply; notice that client does not need to wait for the response in the Writeback phase). This is critical to its great performance especially since Basil can finish a transaction through the fast path 96% of the time in TPCC.
Due to its splendid performance (especially its low latency), in Basil, conflicting transactions are less likely to happen, making it less bottlenecked on contention.
Weakness
The performance of Basil deviates far from state-of-the-art trusted replication protocols with concurrency control and sharding like TAPIR by huge margin. Many of the causes are inherent to all BFT protocols: the cost of generating signatures (Basil’s performance improves by $3.7\times$ to $4.6\times$ after removing all cryptography proofs); the cost to keep additional replicas (instead of $n\ge2f+1$ common in trusted replication systems); the additional read cost to preserve Byzantine independence ($f+1$ matching versions, etc).
Basil assumes $n\ge5f+1$ replicas per shard. This is a rather strong assumption compared with other BFT protocols such as HotStuff and PBFT ($n\ge3f+1$).
Since transactions are driven by clients in Basil, batching transactions is impossible. In its evaluation, this paper compares Basil to HotStuff with batch size of 16 and PBFT with batch size of 64, but in the original HotStuff paper uses a batch size of 100-400, leading to much higher throughput. Notice that, despite that larger batch size can lead to higher latency, throughput is more critical than latency in most BFT applications.
The experiment setup in this paper did not use geo-distributed machines: the network latency is low so contention is less likely to happen. In this setting, OCC provides great performance, whereas a real-world BFT system is likely to have more conflicts.
Florian Suri-Payer, Matthew Burke, Zheng Wang, Yunhao Zhang, Lorenzo Alvisi, and Natacha Crooks. 2021. Basil: Breaking up BFT with ACID (transactions). In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21). Association for Computing Machinery, New York, NY, USA, 1–17. DOI:https://doi.org/10.1145/3477132.3483552