
Suyan Qu
suyan (at) cs.wisc.eduSearching the Unknown - Alistair Sung
Rammer
25 Feb 2022
Summary
Existing DNN frameworks manages the DNN operators in a data flow graph. The library (e.g. PyTorch) schedules each operator individually and relies on the hardware scheduling (e.g. cuDNN) to exploit parallelism within operators. This two-layer scheduling scheme works well only when the kernel launching time is largely negligible compared to execution time and when there is sufficient intra-operator parallelism to saturate all processing units, but precludes opportunities to run multiple operators in parallel on the same GPU.
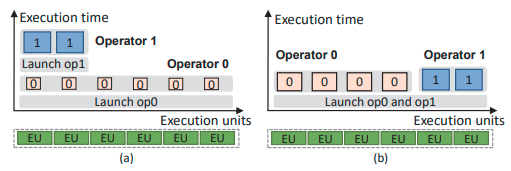
Rammer is a deep learning compiler aimed to unify the inter- and intra-operator scheduling. It defines each DNN operator as rOperator and splits the rOperators into rTasks. A rTask is the smallest unit of scheduling and will run on a single processing unit (e.g., SM in GPU). We can think of rTasks as thread blocks. Rammer also introduces a special rTask, namely barrier rTask, that stalls execution until a set of rTasks has completed. Another abstraction that Rammer provides is rKernels, which corresponds to the actual implementation of rOperators (e.g., if the rOperator is convolution, then rKernel can be matrix multiplication, FFT, etc). Notice that different rKernels will split the rOperator into different rTasks.
Rammer abstracts the hardware as a virtualized parallel device (vDevice, corresponding to GPUs) composed of multiple virtualized execution units (vEU, corresponding to the SMs). This paper achieves single-layer scheduling by assigning rTasks to different vEUs at compile time, and then pin the compiled vEUs on the hardware processing units. From the DNN model, Rammer generates a static execution plan. This plan is broken into multiple parts called rProgram, which is represented as a 2D array of rTasks where the first index represents on which vEU this rTask is assigned to and the second index represents the order in which it will be run on that vEU. Each rProgram runs on a single rDevice. Rammer thereby achieves scheduling over multiple hardware devices (GPUs).
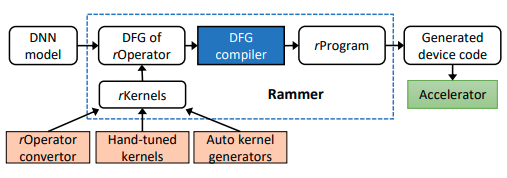
The architecture of Rammer is shown in the figure above. After obtaining the DNN model, Rammer first transforms it to a DFG of rOperators. It does some compile-time profiling to figure out which rKernel is the most efficient through profiling and heuristics. Then the rOperator can be split into rTasks. Rammer uses a Wavefront Scheduling Policy, which is essentially a BFS on the DFG of rOperators. Here wavefront refers to the rTasks that do not depend on any other unscheduled rTasks. The policy iterates through the rTasks in the wavefront and assigns the current rTask to the vEU that becomes available first (based on profiling results). However, if the profiling result shows that assigning the current rTask to the current rProgram does not save execution time, it will put the rTask to a new rProgram that will be run on a different vDevice instead.
Strength
- Rammer exploits the inter- and intra-operator parallelism holistically. It can provide higher GPU utilization compared with traditional two-level scheduling
- The scheduling plan is statically generated, so it does not impose any runtime overhead.
Weakness
- Rammer is only beneficial when there is not sufficient intra-operator parallelism (e.g. in inference workloads) or when the kernel launching overhead is largely negligible. Yet often times neither is true in typical training workloads.
- Rammer can only parallelize two operators if they are independent. With linear models (e.g, ResNet) there is not much Rammer can do.
- Rammer generates scheduling plan statically. If the underlying hardware changes dynamically (e.g., shared between multiple models in data centers), it cannot adapt to the changes.
Ma, Lingxiao, et al. "Rammer: Enabling Holistic Deep Learning Compiler Optimizations with {rTasks}." 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). 2020.